геопространственных решений
сб-вс: Выходной
Исследование нового метода дешифрирования с использованием глубокого обучения на основе изображений GaoFen-2 для аквакультурных районов
Прибрежные аквакультурные районы являются одной из основных территорий добычи морских рыбных ресурсов, уязвимой для штормовых бедствий. Быстрое и точное получение информации о прибрежных аквакультурных районах может помочь в научном управлении и планировании ресурсов аквакультуры. Все больше исследователей уделяют внимание использованию технологий дистанционного зондирования и машинного обучения для немедленного извлечения информации о территории. Однако на спутниковых снимках со средним пространственным разрешением фрагментированные районы аквакультуры после стихийных бедствий распознать нелегко. Поэтому очень важно извлекать аквакультурные районы с помощью изображений с высоким разрешением.
В этой статье мы выделили два основных типа аквакультурных районов: район клеточной культуры и район плотовой культуры (рис. 1). На снимках дистанционного зондирования с высоким разрешением область клеточной культуры выполнена из пластика, имеет более яркий оттенок, выглядит, как неровный прямоугольник, и можно четко наблюдать небольшие сетчатые клетки в области клеточной культуры. На оптических изображениях есть небольшие световые точки на краю области культуры плота. Отражательная способность зоны культуры плота ниже, чем у морской воды. Как правило, этот тип аквакультурных зон расположен вместе и выглядит, как темный и более однородный прямоугольник.

В настоящее время существует множество методов извлечения этих видов аквакультурных площадей, основанных на снимках дистанционного зондирования с умеренным разрешением. Некоторые исследователи определили области аквакультуры на основе экспертного опыта; некоторые ученые автоматически извлекают прибрежные аквакультурные районы на основе коэффициента отражения оптических изображений, коэффициента обратного рассеивания радиолокационных изображений с синтетической апертурой (SAR) и геометрии аквакультурных районов. Кроме того, в последних исследованиях задействовали данные ZiYuan-3 с использованием метода пороговой сегментации для извлечения областей аквакультуры ограждения на основе градиентного преобразования.
Однако на снимках дистанционного зондирования с умеренным разрешением трудно наблюдать районы аквакультуры, разрушенные штормовым приливом, которые не могут удовлетворить потребности реагирования на чрезвычайные ситуации. Поэтому некоторые исследователи изучали извлеченный метод, основанный на снимках дистанционного зондирования с высоким разрешением. Некоторые исследователи использовали текстурные особенности и высокочастотную информацию аквакультурных районов и приняли пороговое обнаружение, которое в основном используется для изображений дистанционного зондирования с высоким разрешением для распознавания целей.
Другие ученые осуществили извлечение аквакультурных площадей путем математического преобразования изображений, таких, как преобразование анализа главных компонентов (PCA), преобразование соответствия и преобразование отношения. Однако при использовании традиционных методов классификации на пиксельном уровне границы результатов добычи аквакультурных районов не ясны, и легко ошибочно принять суда и другие плавучие средства за аквакультурные районы. Кроме того, если в морской воде будет больше отложений, результаты добычи будут нарушены. Между тем, из-за структуры области клеточной культуры и высокого пространственного разрешения ее внутренний зазор будет неправильно распознан (рис. 2).

Чтобы решить упомянутые выше проблемы, мы использовали глубокое обучение для улучшения качества обработки. Глубокое обучение охватывает несколько задач анализа изображений, включая индексацию, сегментацию и обнаружение объектов. В данной работе мы в основном использовали сематическую сегментационную сеть, которая представляет собой метод интерпретации изображений на пиксельном уровне, для извлечения аквакультурных областей. Мы выбрали в качестве источника данных спутниковый снимок GaoFen-2 и исследовали новую семантическую сегментационную сеть Hybrid Dilated Convolution U-Net (HDCUNet) для извлечения прибрежных аквакультурных районов, чтобы избежать недостатков, вызванных традиционной пиксельной классификацией.
Мы исследовали метод дешифрирования с помощью изображения GaoFen-2, полученного 22 июня 2016 года. Центральная географическая координата составляет 119°54EE 26°42NN. Основная экспериментальная зона расположена в заливе Санду города Нинде провинции Фуцзянь, где имеется большая площадь прибрежных аквакультурных районов. Китайский спутник GaoFen-2 — это первый субметровый гражданский оптический спутник дистанционного зондирования Земли. Спутник оснащен панхроматической камерой с пространственным разрешением 0,8 м и мультиспектральной камерой с пространственным разрешением 3,6 м, обладающей характеристиками субметрового пространственного разрешения, высокой точностью позиционирования, возможностью быстрого маневрирования и т. д. В данной работе мы использовали изображение GaoFen-2 после слияния изображений с пространственным разрешением 0,8 м.
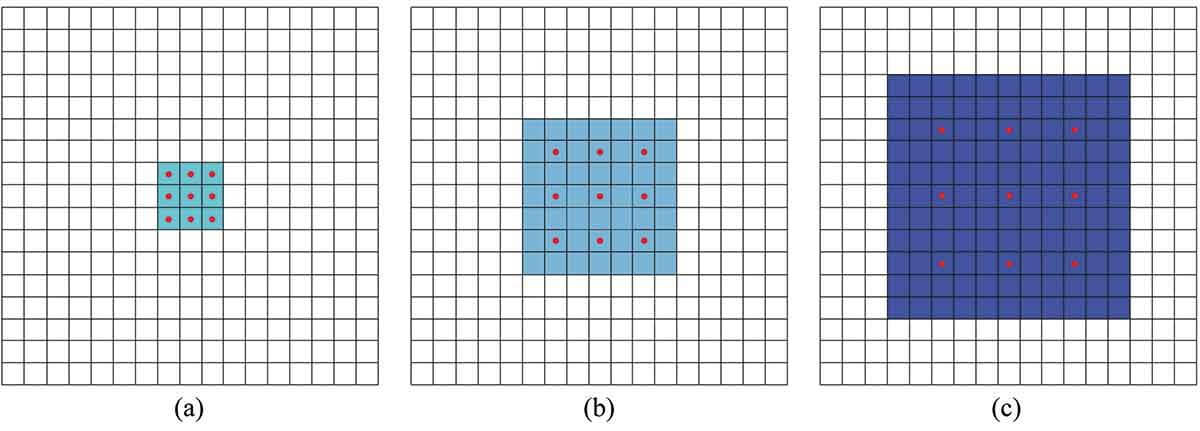
Как важная концепция в глубоком обучении, рецептивное поле относится к размеру входного пространства, отображаемого объектом в сверточной сети. Размер восприимчивого поля показывает, сколько информации содержат извлеченные объекты. Чем больше информации содержит извлеченный объект, тем больше вероятность того, что пиксель будет правильно классифицирован. Для одного и того же изображения, если размер рецептивного поля меньше, труднее правильно классифицировать пиксели в рецептивном поле, которые могут принадлежать к области культуры плота или другим категориям (рис. 3). Напротив, легче судить о том, что пиксели в красном квадрате принадлежат области культуры плота.

Наиболее распространенным методом улучшения размера рецептивного поля является использование сложенных сверточных слоев или слоев объединения, недостатком которых является то, что пространственный размер каждой карты объектов значительно уменьшается, что приводит к неизбежной потере информации о пространственном распределении. По сравнению с тем, как слой объединения или слой свертки шага увеличивает восприимчивое поле, расширенная свертка не изменяет пространственный размер при расширении восприимчивого поля, что более способствует сквозной работе.
По сравнению с традиционной, расширенная свертка имеет параметр, называемый скоростью расширения, который относится к числу «дырок» (нулей), вставленных между соседними параметрами исходного ядра свертки. Контролируя величину скорости расширения, можно одновременно поддерживать пространственный размер карты объектов и улучшать размер рецептивного поля (рис. 4). Другими словами, расширенная свертка принимает во внимание роль слоев свертки и объединяющих слоев.
Однако расширенная свертка приводит к двум потенциальным проблемам:
1. Проблема «сетки». Под влиянием «сетки» расширенное ядро свертки не является непрерывным и не все пиксели используются для расчета, что приводит к потере непрерывности информации (рис. 5). Это крайне опасно для задачи прогнозирования на пиксельном уровне.
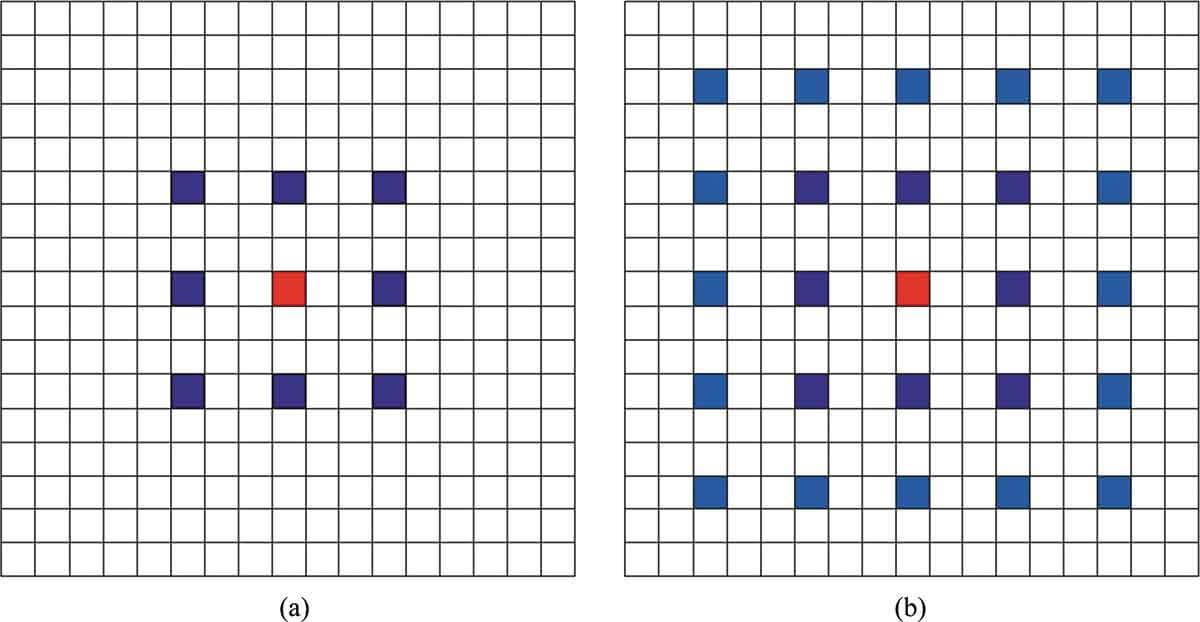
2. Информация в большом восприимчивом поле может оказаться неэффективной для целей малого размера. Использование большой скорости дилатации для получения широкого спектра информации может работать только для извлечения некоторых крупных мишеней. Но для целей малого размера большая скорость расширения может быть контрпродуктивной и невыгодной. Поэтому при проектировании подходящей расширенной свертывающей сети важно учитывать различные размеры мишеней.
Поэтому нами была сконструирована гибридная расширенная свертка (HDC) для преодоления этих недостатков, цель которой состоит в том, чтобы позволить конечному размеру рецептивного поля после серии расширенных сверточных операций полностью покрыть всю площадь без каких-либо отверстий.
Во-первых, среди существующих сетей семантической сегментации U-Net имеет относительно меньшее количество сетевых параметров, поэтому ее временные затраты на обучение и прогнозирование ниже, что удобно для реагирования на чрезвычайные ситуации. Поэтому мы выбрали U-Net для улучшения. Во-вторых, учитывая, что донные отложения, суда и другие плавучие объекты на поверхности воды легко спутать с аквакультурными районами на снимках дистанционного зондирования с высоким разрешением, мы должны сбалансировать цели малого и большого размера, чтобы избежать неправильной идентификации при одновременном выполнении требований сегментации объектов различного размера. Таким образом, мы приняли HDC для улучшения и выбрали классическую комбинацию скорости дилатации.
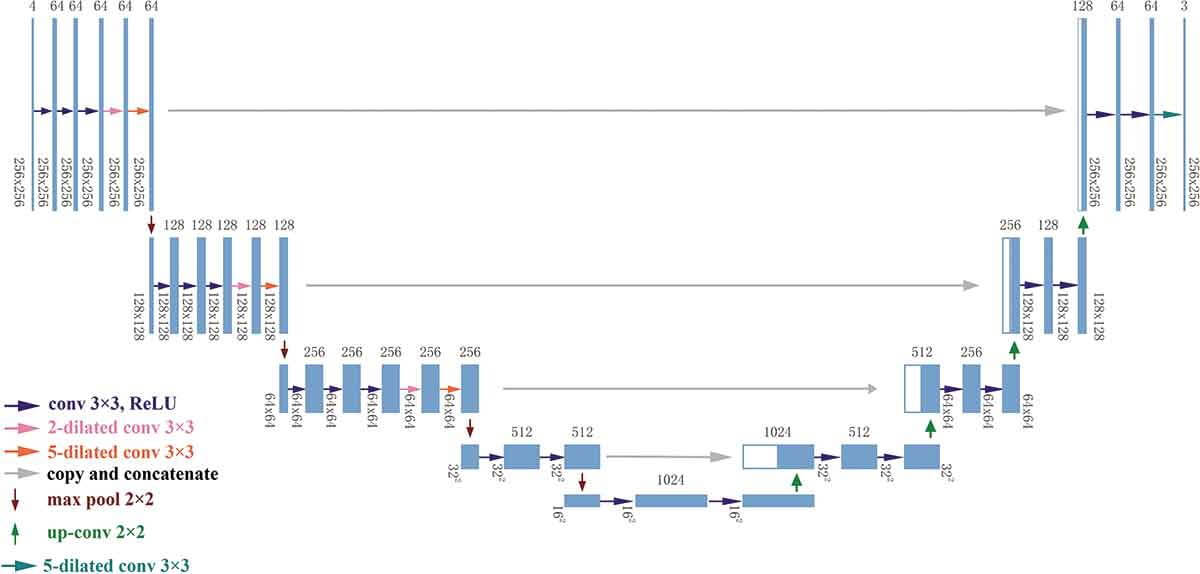
В соответствии с U-Net, HDC, существующим опытом и теориями мы разработали новую семантическую сегментационную сеть, назвав ее гибридной расширенной сверткой U-Net, сокращенно HDCUNet (рис. 6).
В качестве экспериментальной мы выбрали область размером 5218×5218 пикселей, содержащую больше осадков и плавучести, и использовали построенный нами набор образцов (рис. 7). А потом мы использовали HDCUNet для извлечения аквакультурных площадей и провели сравнительные эксперименты с другими методами дешифрирования.

Мы выбрали четыре области из изображения GaoFen-2, отличные от экспериментальной области, с размером 2000×2000 пикселей для маркировки категорий. После разметки, учитывая потребность входного пространства сети, мы произвольно вырезали эти изображения и соответствующие метки на 10 000 патчей с 256×256 пикселями. TensorFlow 1.8 и Keras 2.2 были использованы для построения фреймворка HDCUNet, а для обучения всех вариантов мы используем стохастический градиентный спуск (SGD) с фиксированной скоростью обучения 0,001 и импульсом 0,9.
В данной работе мы использовали три вида критериев оценки точности, включая погрешность, рекал и оценку F1. Точность может помочь нам выяснить вероятность того, что пиксели, которые являются областями аквакультуры в реальности, были правильно извлечены. Отзыв может помочь выяснить вероятность того, что они были извлечены неправильно в пикселях, которые были извлечены как области аквакультуры. И F1-score — это показатель, используемый в статистике для измерения точности двоичной модели, которая учитывает погрешность и рекал.
Мы использовали различные методики для дешифрирования областей аквакультуры и полученный экспериментальный участок (рис. 8). И мы приняли ту же самую обучающую выборку для обучения этих моделей и классифицировали ту же самую экспериментальную область на основе четырех графических процессоров.

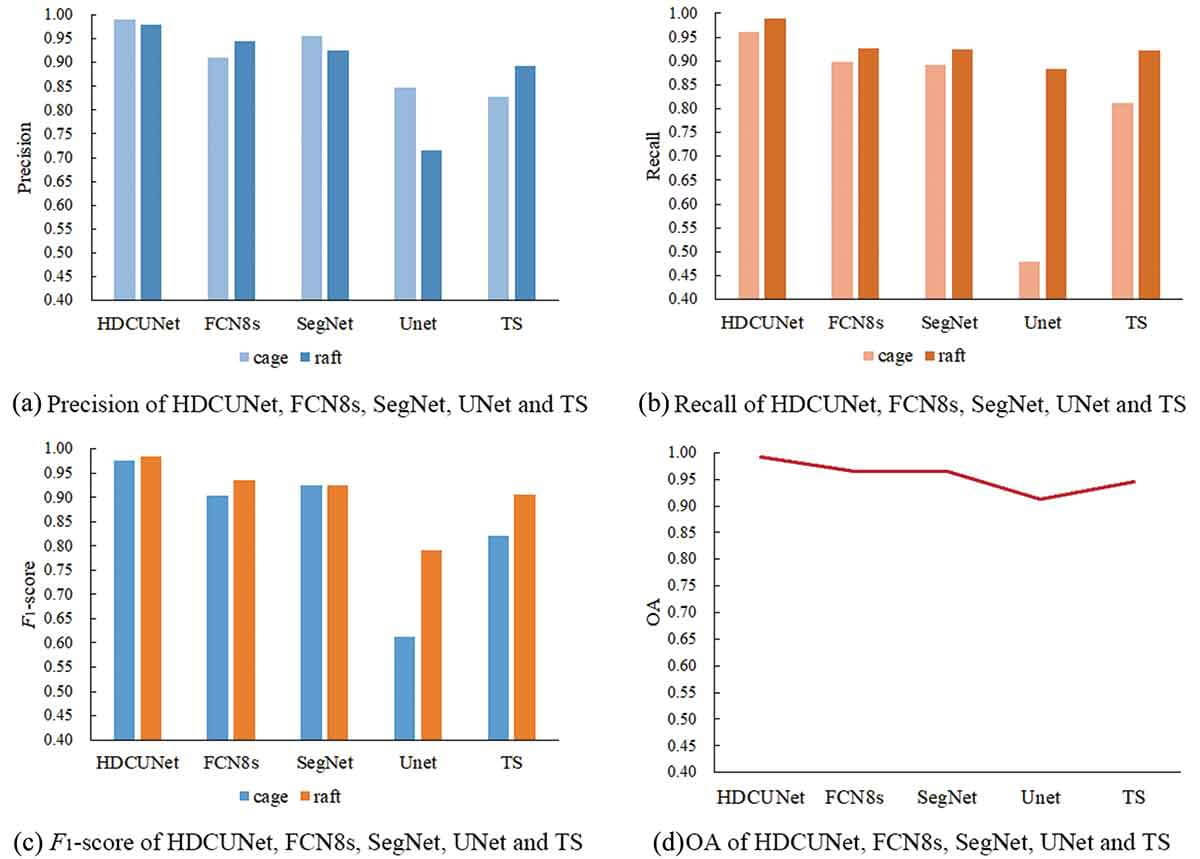
Интуитивно видно, что TS имеет большую фрагментацию, U-Net неправильно классифицирует некоторые области клеточной культуры в область плотовой культуры, а некоторые области аквакультуры не могут быть извлечены SegNet и FCN-8S (рис. 8). Чтобы точно сравнить эти пять методов, мы подсчитали матрицу путаницы каждого метода и получили отчет о классификации. Согласно матрицам путаницы, мы можем вычислить общую точность (OA) HDCUNet, FCN-8S, SegNet, U-Net и TS — 99,16%, 96,57%, 96,51%, 91,17% и 94,61% соответственно. А погрешность, рекал и F1-балл HDCUNet составляют более 95%, а эти критерии площади культуры плота — более 97%.
Чтобы доказать обоснованность нашего подхода, мы подсчитали время обучения каждого метода. Очевидно, что время классификации каждого метода почти одинаково, а разница между максимальным и минимальным временем обучения составляет около 10 минут, что означает, что HDCUNet имеет небольшой недостаток во временной эффективности.
Кроме того, для более интуитивного соблюдения каждого критерия оценки точности этих методов составляются соответствующие статистические диаграммы (рис. 9). ОА каждого метода превышает 90%, но погрешность и рекал двух типов аквакультурных зон, основанных на данных методах, не вполне удовлетворительны. По сравнению с TS, погрешность, рекал и F1-оценка двух типов аквакультурных площадей, извлеченных HDCUNet, повышены более чем на 10%.
Во-первых, по сравнению с TS, HDCUNet имеет следующие четыре преимущества:
1. Результаты извлечения имеют более четкие границы. Видно, что границы результатов, полученных HDCUNet, более четкие, в то время как границы результатов извлечения TS окружены большим количеством патчей пиксельного уровня (рис. 10).

2. Ослабить влияние отложений в морской воде на результаты добычи. Интуитивно видно, что некоторые отложения были ошибочно приняты за аквакультурные районы на основе TS, чего можно избежать с помощью HDCUNet (рис. 11).

3. Избежать влияния судов и других отснятых материалов (рис. 12). Если мы используем TS для извлечения аквакультурных районов, корабли и другие кадры на поверхности воды будут ошибочно приняты за аквакультурные районы. Но если мы будем использовать HDCUNet, то этой проблемы можно будет избежать.

4. Избежать неправильного определения внутреннего зазора зоны культивирования клеток (рис. 13). Благодаря структуре клеточной культуральной области и высокому пространственному разрешению ее внутренний зазор не будет легко распознан, если мы извлечем его с помощью TS. Однако, если мы примем HDCUNet, эта ошибочная идентификация будет устранена.

Таким образом, HDCUNet не только преодолевает некоторые недостатки традиционных методов, но и значительно повышает точность классификации по сравнению с U-Net, а также превосходит FCN-8S и SegNet по трем показателям точности.
сб-вс: Выходной