of geospatial solutions
Sat-Sun: Non-working days
Research on a New Deep Learning-Based Decoding Method Using GaoFen-2 Images for Aquaculture Zones
Coastal aquaculture zones are among the primary areas for harvesting marine fishery resources, vulnerable to storm disasters. Rapid and accurate information retrieval about coastal aquaculture zones can aid in scientific management and resource planning of aquaculture. Increasingly, researchers are focusing on the use of remote sensing technologies and machine learning for immediate extraction of territory information. However, fragmented aquaculture zones after natural disasters are difficult to recognize in satellite images with moderate spatial resolution. Therefore, it is crucial to extract aquaculture zones using high-resolution images.
In this article, we distinguish two main types of aquaculture zones: cage culture zones and raft culture zones (Fig. 1). In high-resolution remote sensing images, the cage culture area, made of plastic, appears brighter and resembles an irregular rectangle with clearly visible small mesh cells within the cage culture zone. Optical images show small bright spots at the edge of the raft culture area. The reflectivity of the raft culture zone is lower compared to the seawater. Typically, this type of aquaculture zone is clustered together and appears as a dark and more uniform rectangle.
Currently, there are numerous methods for extracting these types of aquaculture areas based on moderate-resolution remote sensing images. Some researchers identify aquaculture areas based on expert experience, while others automatically extract coastal aquaculture zones using coefficients of reflection from optical images, backscattering coefficients from synthetic aperture radar (SAR) images, and the geometry of aquaculture zones. Recent studies have also utilized ZiYuan-3 data with threshold segmentation methods to extract cage aquaculture areas based on gradient transformation.
However, it is challenging to observe aquaculture areas destroyed by storm tides in moderate-resolution remote sensing images, which cannot meet the needs of emergency response. Therefore, some researchers have explored methods based on high-resolution remote sensing images. They have used textural features and high-frequency information of aquaculture areas and applied threshold detection primarily for high-resolution remote sensing images to recognize targets.
Other researchers have extracted aquaculture areas through mathematical transformations of images, such as principal component analysis (PCA), matching transformation, and ratio transformation. However, traditional pixel-level classification methods often result in unclear boundaries of aquaculture extraction and can easily mistake ships and other floating objects for aquaculture areas. Additionally, if there are more deposits in the seawater, the extraction results will be disrupted. Meanwhile, due to the structure of the cage culture area and its high spatial resolution, its internal gap can be incorrectly identified (Fig. 2).

To address the aforementioned issues, we employed deep learning to enhance the processing quality. Deep learning encompasses several image analysis tasks, including indexing, segmentation, and object detection. In this study, we primarily used a semantic segmentation network, which interprets images at the pixel level, to extract aquaculture areas. We chose GaoFen-2 satellite imagery as our data source and investigated a new semantic segmentation network called Hybrid Dilated Convolution U-Net (HDCUNet) for extracting coastal aquaculture areas, aiming to overcome the shortcomings of traditional pixel-level classification.
Our research focused on deciphering GaoFen-2 imagery taken on June 22, 2016, with the central geographic coordinates at 119°54E and 26°42N. The main experimental zone was located in Sandu Bay, Ningde City, Fujian Province, where there is a large area of coastal aquaculture regions. GaoFen-2 is China's first civil optical Earth observation satellite with sub-meter spatial resolution capabilities. It is equipped with a panchromatic camera (0.8 m spatial resolution) and a multispectral camera (3.6 m spatial resolution), providing high-precision positioning, rapid maneuverability, and other advanced features. In this study, we utilized GaoFen-2 imagery post-merging with a spatial resolution of 0.8 m.
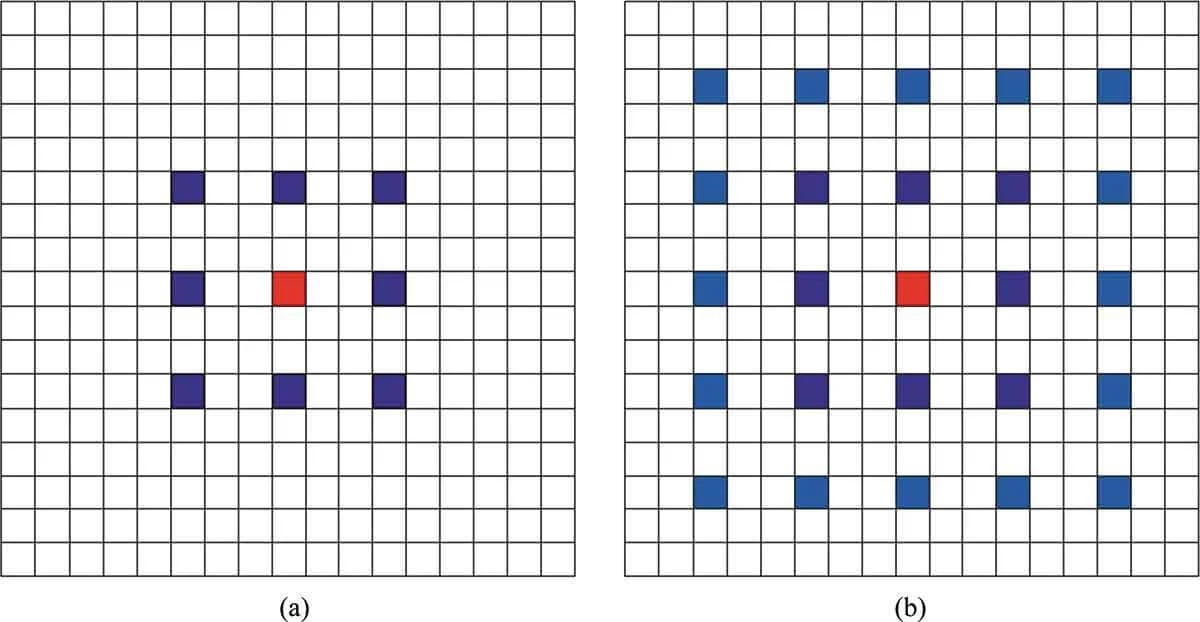
Receptive field is an important concept in deep learning, referring to the size of the input space that a convolutional network object maps. The size of the receptive field indicates how much information is contained in the extracted objects. The more information an extracted object contains, the higher the likelihood that pixels will be correctly classified. For the same image, if the receptive field size is smaller, it becomes more challenging to correctly classify pixels within the receptive field, which may belong to either the raft culture area or other categories (Fig. 3). Conversely, it is easier to determine that pixels in the red square belong to the raft culture area.
The most common method to enhance the size of the receptive field is through the use of dilated convolutional layers or pooling layers, which unfortunately reduce the spatial dimensions of each feature map, inevitably leading to loss of spatial distribution information. In contrast to how pooling or convolutional layers increase the receptive field size but reduce spatial dimensions, dilated convolution does not change spatial dimensions while expanding the receptive field, which promotes end-to-end operations.
Compared to traditional methods, dilated convolution introduces a parameter called dilation rate, which refers to the number of "holes" (zeros) inserted between adjacent parameters of the original convolution kernel. By controlling the dilation rate, it's possible to simultaneously maintain the spatial dimensions of the feature map and enhance the size of the receptive field (Fig. 4). In other words, dilated convolution integrates the roles of convolutional and pooling layers.

However, dilated convolution introduces two potential issues:
1. Grid artifact problem. Due to the "grid" effect, the dilated convolution kernel is not continuous, and not all pixels are utilized in calculation, leading to discontinuities in information (Fig. 5). This can be particularly problematic for pixel-level prediction tasks.
2. Inefficiency of large receptive fields for small-scale targets. Using a high dilation rate to capture a wide range of information may work well for extracting larger targets, but it can be counterproductive and inefficient for smaller-scale targets. Therefore, when designing an appropriate dilated convolutional network, it is important to consider different target sizes.
To address these issues, we designed a Hybrid Dilated Convolution (HDC) to ensure that after a series of dilated convolution operations, the final receptive field size fully covers the entire area without any gaps.
Firstly, among the existing semantic segmentation networks, U-Net has relatively fewer network parameters, resulting in lower training and prediction time, which is convenient for responding to emergencies. Therefore, we chose U-Net for enhancement. Secondly, considering that seabed sediments, vessels, and other floating objects on the water surface can easily be mistaken for aquaculture areas in high-resolution remote sensing images, we must balance the goals of small and large target sizes to avoid incorrect identification while meeting segmentation requirements for objects of different sizes. Thus, we adopted HDC to enhance and chose a classic combination of dilation rates.
Building upon U-Net, HDC, existing experiences, and theories, we developed a new semantic segmentation network named Hybrid Dilated Convolution U-Net, abbreviated as HDCUNet (Fig. 6).
As an experiment, we selected a region measuring 5218×5218 pixels, containing more sediments and floating objects, and used our constructed dataset (Fig. 7). Subsequently, we employed HDCUNet to extract aquaculture areas and conducted comparative experiments with other decryption methods.

We selected four regions from the GaoFen-2 image, different from the experimental area, each measuring 2000×2000 pixels, for labeling categories. After annotation, considering the network's input space requirement, we randomly cropped these images and corresponding labels into 10,000 patches of 256×256 pixels. TensorFlow 1.8 and Keras 2.2 were used to construct the HDCUNet framework, and for training all variants, we employed stochastic gradient descent (SGD) with a fixed learning rate of 0.001 and momentum of 0.9.
In this study, we employed three types of accuracy assessment criteria, including accuracy, recall, and F1 score. Accuracy helps determine the likelihood that pixels identified as aquaculture areas are correctly extracted. Recall helps identify the likelihood of incorrectly extracting pixels that should have been identified as aquaculture areas. The F1 score is a metric used in statistics to measure the accuracy of a binary classification model, balancing precision and recall.
We used various decryption methods for aquaculture areas and evaluated the experimental section (Fig. 8). We utilized the same training dataset to train these models and classified the same experimental area based on four graphical processors.
Intuitively, TS exhibits higher fragmentation, U-Net misclassifies some cell culture areas as raft culture areas, and some aquaculture areas cannot be extracted by SegNet and FCN-8S (Fig. 8). To precisely compare these five methods, we computed the confusion matrix for each method and obtained classification reports. According to the confusion matrices, the overall accuracy (OA) for HDCUNet, FCN-8S, SegNet, U-Net, and TS is 99.16%, 96.57%, 96.51%, 91.17%, and 94.61%, respectively. The precision, recall, and F1-score for HDCUNet are above 95%, and these criteria for raft culture areas are above 97%.
To substantiate our approach, we measured the training time for each method. It's evident that the classification time for each method is almost the same, with a difference of about 10 minutes between the maximum and minimum training times, indicating HDCUNet has a slight disadvantage in terms of time efficiency.
Additionally, for a more intuitive observation of each accuracy criterion, corresponding statistical diagrams are compiled (Fig. 9). The OA of each method exceeds 90%, but the precision, recall, and F1-score for the two types of aquaculture areas based on these methods are not entirely satisfactory. Compared to TS, the precision, recall, and F1-score for the two types of aquaculture areas extracted by HDCUNet are improved by more than 10%.
First, compared to TS, HDCUNet has the following four advantages:
1. The extraction results have clearer boundaries. It can be seen that the boundaries of the results obtained by HDCUNet are sharper, whereas the boundaries of TS extraction results are surrounded by more pixel-level patches (Fig. 10).
2. Mitigate the influence of sediment deposits in seawater on extraction results. It is intuitive that some sediment deposits were mistakenly identified as aquaculture areas based on TS, which can be avoided with HDCUNet (Fig. 11).
3. Avoid the influence of ships and other floating materials (Fig. 12). If we use TS to extract aquaculture areas, ships and other objects on the water surface may be mistakenly identified as aquaculture areas. However, using HDCUNet can help mitigate this issue.
4. Avoid misidentifying the inner gap of cell cultivation zones (Fig. 13). Due to the structure of the cell cultivation area and its high spatial resolution, the inner gap will not be easily recognized if extracted using TS. However, adopting HDCUNet can eliminate this misidentification.

Thus, HDCUNet not only overcomes some drawbacks of traditional methods but also significantly improves classification accuracy compared to U-Net, and outperforms FCN-8S and SegNet across three accuracy metrics.
Sat-Sun: Non-working days